Intr-o sera sau intr-un solar, multe decizii par simple pana cand vremea, umiditatea, temperatura si ritmul culturii se schimba in acelasi timp. Un cultivator vede plantele, simte aerul, stie istoricul locului si poate observa repede cand ceva nu este in regula. Totusi, ochiul uman nu poate sta permanent in cultura, iar diferentele dintre noapte si zi, dintre o zona umbrita si una expusa sau dintre doua irigari pot ramane ascunse pana cand efectul apare vizibil pe planta.
GrowGuard porneste de la ideea ca datele trebuie sa fie utile, nu doar multe. Platforma strange informatii din senzori LoRaWAN, NB-IoT, MQTT sau TTN API, le aseaza pe harta, le coreleaza cu forecastul si le transforma in alerte, istoric, rapoarte si prioritati de lucru. In loc sa verifici fiecare senzor separat, vezi rapid unde cultura se indeparteaza de intervalul normal si ce merita verificat in teren.
Acest articol explica modul in care monitorizarea live poate deveni un instrument de decizie pentru sere, solarii, floricultura, legumicultura si alte culturi horticole. Nu este vorba despre a inlocui experienta cultivatorului, ci despre a-i da un tablou mai clar: ce se intampla, unde se intampla, de cat timp si ce poate fi facut mai devreme.
De la citiri izolate la context agronomic
O citire de temperatura sau umiditate este utila doar daca stii unde a fost masurata, cand a aparut si cum se compara cu restul culturii. O valoare ridicata pentru umiditate poate fi normala dupa irigare, dar poate deveni risc daca ramane ridicata noaptea, cand ventilatia scade si frunzele raman ude. O temperatura buna la nivelul aerului nu spune totul daca zona radiculara este rece sau daca diferenta intre doua zone ale serei este mare.
GrowGuard pune aceste valori in context. Harta senzorilor arata pozitia, dashboardul arata starea curenta, iar istoricul arata daca un episod este accidental sau repetitiv. Cand datele sunt privite impreuna, decizia nu mai porneste de la impresie, ci de la un model simplu: ce s-a schimbat, cat de mult s-a schimbat si care este zona in care merita intervenit prima data.
Ce poate masura o cultura monitorizata corect
In functie de senzorii conectati, GrowGuard poate urmari temperatura aerului, umiditatea aerului, temperatura solului, umiditatea solului, EC, pH, baterie, stare senzor, valori venite prin payloaduri LoRaWAN, NB-IoT sau MQTT si alte masuratori utile pentru cultura. Pentru sere si solarii, combinatia dintre aer, radacina si forecast este importanta pentru ca planta raspunde la intregul mediu, nu la un singur indicator.
Un exemplu practic este diferenta dintre doua zone ale aceleiasi sere. Daca o zona are umiditate mai mare si temperatura usor mai scazuta, riscul fitosanitar poate creste local, chiar daca media generala pare buna. Daca un senzor de sol arata umiditate ridicata dar cultura continua sa sufere, problema poate fi temperatura radiculara, aerarea substratului, EC sau strategia de irigare. Monitorizarea buna nu da automat raspunsuri absolute, dar te ajuta sa pui intrebarile corecte.
Cum ajuta senzorii LoRaWAN, NB-IoT si MQTT
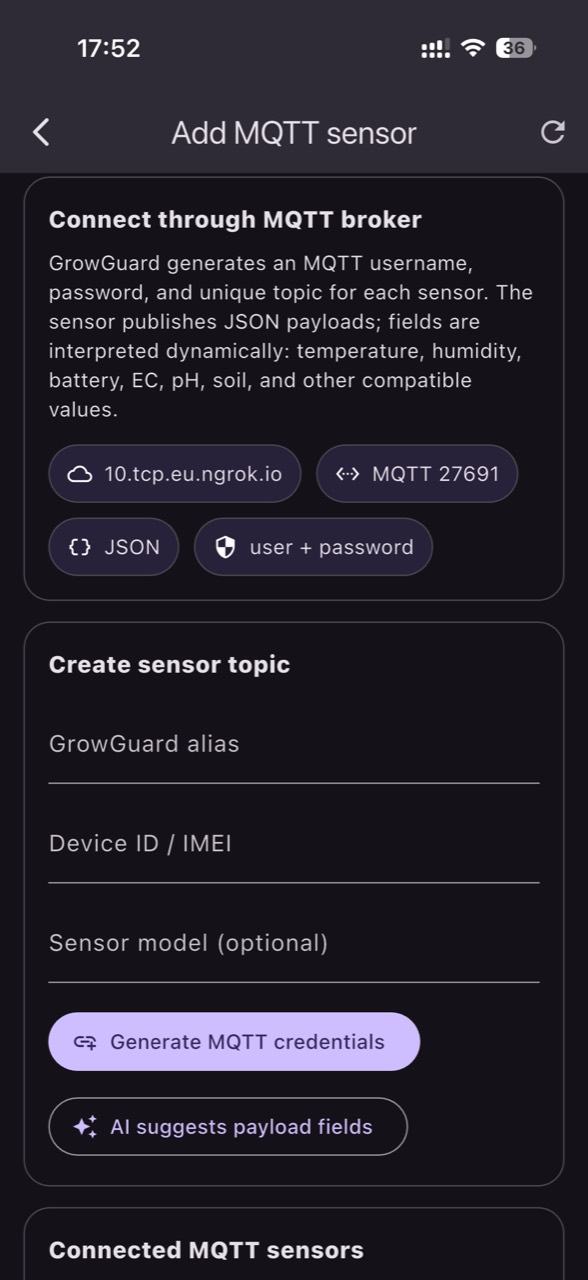
In agricultura si horticultura, conectivitatea conteaza la fel de mult ca senzorul. LoRaWAN este potrivit pentru consum redus si distante mari, NB-IoT poate fi util acolo unde exista acoperire celulara stabila, iar MQTT este frecvent in integrari tehnice, gateway-uri si sisteme deja existente. GrowGuard este construit sa primeasca date din mai multe surse, astfel incat fermierul sau integratorul sa nu fie blocat intr-o singura arhitectura.
Pentru utilizator, partea importanta nu este protocolul in sine, ci faptul ca datele ajung intr-o forma usor de citit. GrowGuard poate lucra cu device-uri existente, poate importa aplicatii TTN prin API si poate ajuta la interpretarea payloadurilor prin AI, cu validarea utilizatorului inainte de salvare. Asta reduce timpul dintre instalarea senzorului si momentul in care el devine util in decizie.
Alertele bune reduc verificarea inutila
Fara alerte, monitorizarea devine inca o lista pe care cineva trebuie sa o verifice zilnic. Cu alerte prost configurate, sistemul devine zgomotos si utilizatorul incepe sa le ignore. O alerta buna trebuie sa fie clara, legata de un prag relevant si suficient de specifica incat sa indice unde sa te uiti. In GrowGuard, alerta poate fi asociata cu un senzor, o zona, un indicator sau un risc explicat prin context.
De exemplu, o alerta de umiditate ridicata nu trebuie citita automat ca problema. Ea poate fi un semn ca ventilatia trebuie verificata, ca o folie ramane prea mult inchisa, ca irigarea a fost facuta tarziu sau ca forecastul anunta o noapte rece. Valoarea reala apare atunci cand alerta duce la o verificare concreta si la o decizie mai rapida decat ar fi fost posibil doar prin observatie vizuala.
Harta senzorilor si diferenta dintre zone
Multe culturi nu sunt uniforme. Intr-o sera lunga, capetele pot avea comportament diferit fata de mijloc. Intr-o livada, o parcela poate avea expunere diferita la vant. Intr-o vie, solul si panta pot schimba complet retentia apei. Harta senzorilor din GrowGuard ajuta utilizatorul sa vada datele in locul lor real, nu doar intr-un tabel.
Aceasta perspectiva ajuta mai ales cand trebuie prioritizata munca. Daca trei senzori arata abateri, harta arata daca problema este concentrata intr-o zona sau raspandita. Daca abaterea apare mereu in acelasi loc, poate fi o problema de ventilatie, irigare, drenaj sau amplasare. Cand datele au locatie, discutiile din echipa devin mai precise: mergem la zona X, verificam senzorul Y si comparam cu istoricul ultimelor zile.
Forecastul schimba modul in care citesti datele
O valoare curenta este doar inceputul. Daca forecastul anunta o noapte rece, o umiditate ridicata se interpreteaza diferit. Daca urmeaza zile calde, stresul hidric poate aparea mai repede. Daca presiunea de boala este favorizata de temperatura si umezeala, decizia de aerisire, irigare sau verificare in teren trebuie luata inainte ca simptomele sa fie vizibile.
GrowGuard combina monitorizarea cu forecast si istoric pentru a sustine decizii preventive. Nu inseamna ca aplicatia decide in locul cultivatorului, ci ca ii arata unde conditiile se schimba si ce parametri ar trebui observati. Aceasta abordare este utila mai ales in culturi cu valoare ridicata, unde o zi pierduta poate insemna costuri mari sau calitate mai slaba la recoltare.
Rapoarte, istoric si invatare din sezon
Datele live sunt importante in ziua respectiva, dar istoricul este important pentru invatare. Cand poti vedea cum a evoluat temperatura, umiditatea sau EC intr-o perioada mai lunga, incepi sa observi tipare. Poate ca o zona reactioneaza mereu mai tarziu la irigare. Poate ca un anumit interval de noapte produce risc. Poate ca setarile de ventilatie functioneaza bine primavara, dar nu vara.
GrowGuard include istoric, exporturi si rapoarte pentru ca deciziile bune nu sunt doar reactive. Ele se construiesc din comparatii. Un raport poate ajuta la discutia cu echipa, cu un consultant, cu un furnizor de senzori sau cu un partener tehnic. In loc de aproximari, ai o baza comuna: datele masurate si contextul in care au aparut.
Cum incepi practic cu GrowGuard
Un inceput bun nu inseamna sa pui senzori peste tot. Inseamna sa alegi zone reprezentative si indicatori care influenteaza deciziile zilnice. Pentru o sera, poate fi util un pachet minim cu temperatura si umiditate aer, un senzor de sol sau substrat si o pozitionare clara pe harta. Pentru o livada sau vie, amplasarea in zone diferite poate fi mai importanta decat numarul mare de senzori intr-un singur punct.
Dupa instalare, primul obiectiv este calibrarea asteptarilor: ce intervale sunt normale pentru cultura, cand apar abateri, ce alerte sunt utile si cine le primeste. GrowGuard devine mai valoros pe masura ce datele se strang si echipa invata sa le interpreteze. Aplicatia ofera structura, dar rezultatul bun vine din combinatia dintre experienta cultivatorului si informatia masurata constant.
Concluzie
Monitorizarea cu GrowGuard nu este despre a transforma agricultura intr-un ecran plin de cifre. Este despre a vedea mai repede ce se intampla in cultura si a lua decizii mai clare. Senzorii, harta, forecastul, alertele si istoricul lucreaza impreuna pentru a reduce incertitudinea si pentru a directiona atentia acolo unde conteaza.
Pentru sere, solarii, livezi, vii si culturi horticole, diferenta nu vine dintr-o singura masuratoare, ci din continuitate. Cand datele sunt urmarite zi de zi, cultura incepe sa spuna o poveste mai completa. GrowGuard ajuta cultivatorul sa citeasca acea poveste si sa actioneze inainte ca problema sa devina evidenta.